
Earlier today, I presented my CogSci paper Synthesised size/sound sound symbolism. The six page paper is short and to the point, but hey, it technically counts as a publication, so I figure it’d be remiss of me not to render it badly in MS Paint.
We start with the Japanese ideophone learning study. Participants learned some Japanese ideophones, half with their real Dutch translations, half with their opposite translations, and it turned out that they were way better at remembering the ideophones with their real translations. Importantly, this didn’t happen when we did exactly the same thing with regular, arbitrary adjectives. You can read that paper here, and download some of the experiment materials for it here if you want to try it yourself. You can also read the replication study we did with EEG here, and download the data and analysis scripts for that here.
The results looked a bit like this:

But while we can see that there is an obvious effect, we don’t know how it works. Is it a learning boost that people get from the cross-modal correspondences in the real condition?

Or is it a learning hindrance that people get from the cross-modal clashes in the opposite condition?

(or indeed, is it both?)
Without adding a neutral condition where the words neither obviously match nor mismatch their meanings, we don’t really know.
So, we created some synthesised size/sound sound-symbolic pseudowords, which is easier said than done. It’s well known that people associate voiced consonants and low, back vowels with large size, and voiceless consonants and front, high vowels with small size. This is probably because of the mouth shape you make when saying those sounds:
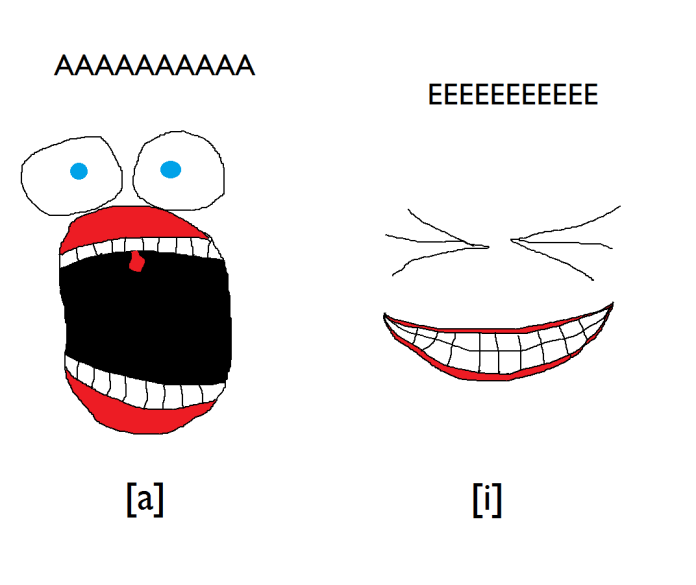
We created big-sounding words (like badobado), small-sounding words (like kitikiti), and neutral-sounding words which were halfway in between (like depedepe).
A neutral condition could tell us if it’s a graded effect…

a match boost effect…

or a mismatch hindrance effect:

Turns out it’s a match boost effect. Participants learned the match pseudowords (e.g. badobado and big, kitikiti and small) better than the neutral pseudowords (e.g. kedekede and big, depedepe and small), but there wasn’t a difference in how well they learned the neutral and mismatch pseudowords (e.g. godagoda and small, tikutiku and big).

For good measure, we did it again with double the original sample size, because it’s nice to check things.
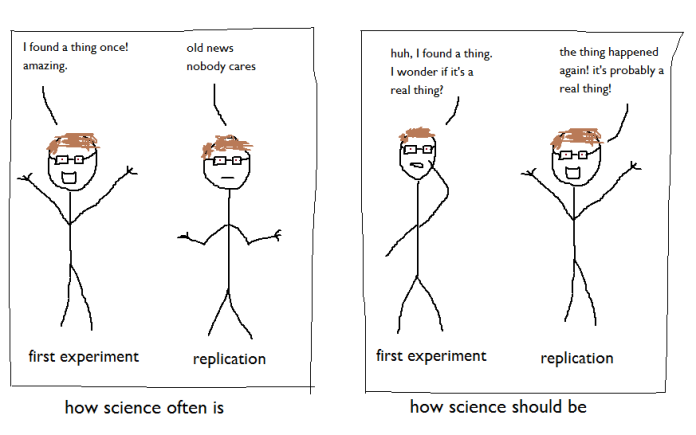
…and, yes, we found exactly the same thing:

So, it looks like it’s a special match boost effect from the cross-modal correspondences, not a graded effect reflecting all cross-modal information.
This is a nice paradigm which can be easily altered to try with different languages or different stimuli, e.g. using big and small shapes rather than the words “big” and “small” in order to rule out letter confounds. I’ll put up all the Presentation scripts, synthesised stimuli, and analysis scripts once I’ve tidied them up a lot (if you think my MS Paint scribbles are messy, you should see my code). It should be pretty straightforward for anybody to download and redo this, so it’d make a good project for a Bachelors/Masters intern. I’d love to see this get taken further and tried out with useful variations and changes. But good luck coming up with a more satisfying title!
